
The keys to success with conversational apps for business
In any conversation about the use of chatbots, digital assistants, and similar tools for business, there is one aspect that should never be overlooked – the issue of data. In this blog post, find out what really counts when it comes to handling data in combination with AI.
Data, methods, and their measurability
Data plays a crucial role in two respects. For one thing, it forms the basic framework used to create the models. Secondly, it is the benchmark against which the application’s performance is measured. The success of any AI project is intricately linked to the available data and the measurability of the method used. If the method fails to deliver the targeted degree of accuracy right from the start, this can have a number of reasons – for instance, when the applied algorithm isn’t suitable for the given data. That’s why it makes sense to compare different methods of model creation, test their accuracy, and optimize the parameters applied.
To properly train the models that you intend to use, you need to start with a comprehensive set of training data. For machine learning, the data is prepared so that it contains the information that needs to be learned – for instance, which part of the sentence refers to a person, an organization, or a date – using markings and labels. If this so-called ground truth contains incorrect and/or incomplete data, it won’t be possible to obtain correct results. Conversation applications like Siri, Alexa, and Cortana use large-scale analysis to measure possible user interactions in order to verify the performance of their services and features. These methods of measuring are particularly well suited for ensuring that upgrades and new features reach a certain acceptance threshold before they are launched. Together with automated tests to secure a particular amount of responses for user acceptance, an adequate and appropriate data set is crucial.
Evaluating the accuracy needs to be front and center whenever an AI solution is being implemented, and no solution should be launched until the intended level of quality has been reached. The targeted accuracy level will vary from company to company and from department to department. An accuracy rate of 80%, for instance, means that correct results are achieved in 80% of cases. Here again, we differentiate between quality and quantity, or rather, between accuracy and completeness. The system either recognizes adequately (quality) or it recognizes everything (quantity). Hence, the extent to which the training data is comprehensive, representative, and of high quality will determine the quality of the responses and thus of the dialogue.
In many cases, crucial improvements can also be achieved when developers cooperate closely with the users. User expertise and feedback delivers valuable input to developers, which they can use during model creation to apply certain features, generate new ones, and feed them into the algorithm. This results in an app that is tailored more effectively to the needs of the users.
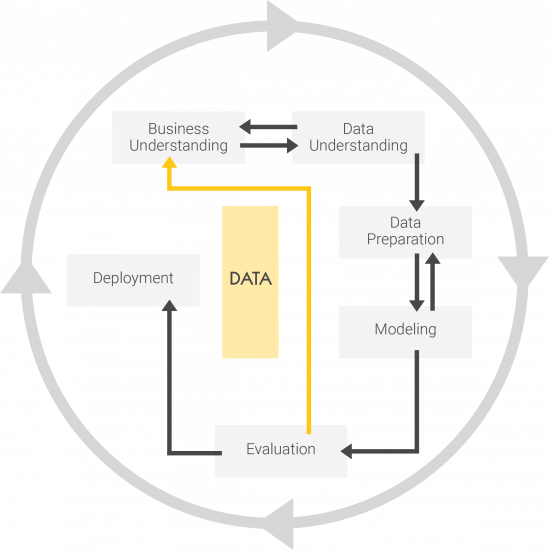
Figure: Process model for understanding data
One approach to minimize the time and effort required to prepare company data is what is known as transfer learning. This approach builds on models that are based on general, publicly available data sets. In other words, the conversation app draws from a comprehensive knowledge base with previously indexed data, documents, languages, catalogs, and error cases. This makes it possible to train a specialized model with a more limited number of company data sets. Nevertheless, this method is subject to the nature of the model. A preliminary evaluation will provide insight into its applicability.
The overview illustrates the advantages of examining the topic of data in depth to ultimately achieve the desired results.

Have you been thinking about how you could use AI in your business? Our AI Guide for Business offers some ideas to get you started:
Download White Paper
Latest Blogs

Inside Insight: How Journeys and Touchpoints Make Enterprise Search Effortless with Mindbreeze Insight Workplace
Picture this: you’re preparing for a high-stakes client meeting.

The Future of Enterprise AI Depends on Smarter RAG Solutions
Today’s enterprise leaders ask how to make AI meaningful, responsible, and scalable. One architectural approach stands out as organizations look beyond isolated proof-of-concepts and begin embedding AI into workflows: Retrieval-Augmented Generation (RAG).