
An Introduction to Text Classification
Text classification, sometimes called “text categorization” or “text tagging” is the process of organizing text based on a set of categories and pinpointing the keywords.
With the help of Natural Language Processing (NLP), Natural Language Understanding (NLU), and Natural Language Question Answering (NLQA), Mindbreeze InSpire can understand human language and identify the predetermined categories of text. The categories can be defined based on what is essential to the user or the business unit handling the solution.
Using training data sets that learn from past experiences makes text classification fairly simple for an insight engine like Mindbreeze InSpire.
Having a machine annotate a file with metadata and identify the pre-defined types of words a user may be searching for gives customers the ability to see the exact parts of the document they need. For example, in a 50-page document, the user’s interested in locations can see where different places are written. A user interested in dates and years can see every month or year reported in the document – the same applies to people, occupations, companies, and more in multiple languages across the world. Because of deep learning algorithms and linguistic interpretation, determining what content means is made possible.
Here is an image of what this looks like below:
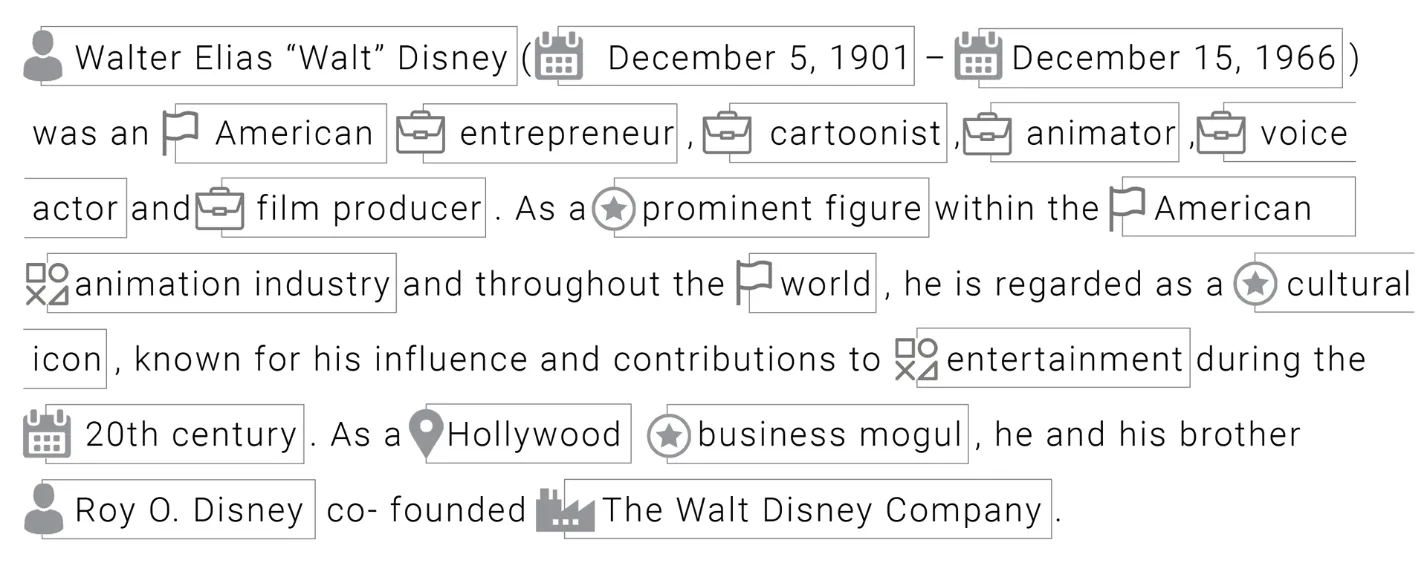
Taxonomies, ontologies, and company catalogs can serve as the basis for the training sets and augment the systems knowledge base, identifying and extracting preferred terminology.
Care to learn more? Contact the Mindbreeze Team today or join us for our upcoming webinar, "Hands-on: How to apply Mindbreeze InSpire Text Classification Insight Service - AI at your fingertips."
Latest Blogs

Boosting Enterprise Intelligence with Tool Calling
Introduction: A New Era of Intelligent SearchMindbreeze understands that enterprise needs have evolved. It is no longer sufficient for AI systems to retrieve documents or surface static answers. Tool calling meets this demand head-on.

Scaling Agentic AI and the Future of Enterprise Intelligence: A Conversation with Daniel Fallmann on The Digital Executive Podcast
AI continues to transform how organizations harness their information—and in the latest episode of The Digital Executive Podcast, our CEO and founder Daniel Fallmann sits down with host Brian Thomas to share how Mindbreeze is setting a new standard with en