
Ingest Data with Mindbreeze InSpire and the Semantic Pipeline
Enterprise data is located in multiple different sources. The process of ingesting data and content refers to transferring scattered data to a single destination. Once ingested with the semantic pipeline and stored in one location, the enterprise can further analyze and process the data.
What is the Semantic Pipeline?
Within Mindbreeze, the semantic pipeline is the process of crawling a document, email, webpage, or other pieces of information for data and metadata. During the “crawling phase,” we use a filter service to enrich and extract data from various disparate sources to build a queryable index of content.
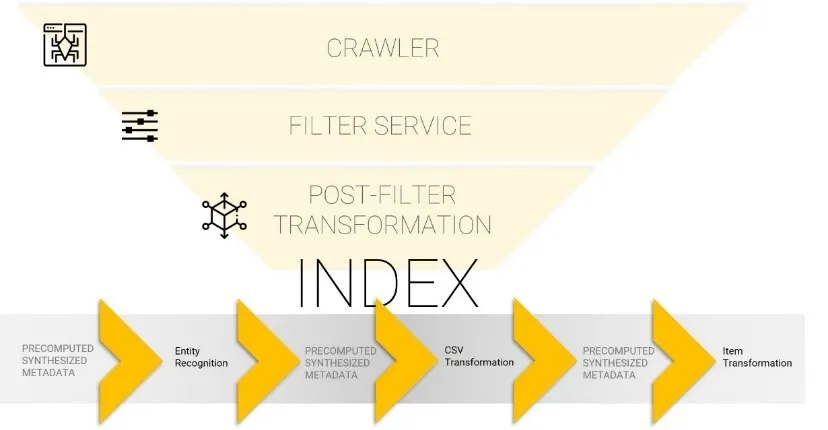
Data Enrichment and Post-Filter Transformation
Data enrichment takes all the raw extracted data and enhances it with relevance. Data enrichment allows for data transformation, as it increases the precision of your existing data with new information in real-time. Improving the accuracy of your data adds more value because it is up-to-date with knowledge from additional third-party sources.
The Post-Filter Transformation step lets us manipulate the ingested content to provide meaning and context to your business.
450+ Connectors
To allow for easy integration within your company, Mindbreeze InSpire offers more than 450 connectors to tie the different data sources together.
All connectors can support the operative and analytical requirements as well as a preselection of relevant datasets. Beyond this, our connectors ensure that all data is synchronized and enriched so that changed documents and updated information is available to your enterprise in real-time.
Want to learn more?
Please do not hesitate to contact us about how Mindbreeze ingests content and extracts data with the semantic pipeline.
Latest Blogs

Inside Insight: How Journeys and Touchpoints Make Enterprise Search Effortless with Mindbreeze Insight Workplace
Picture this: you’re preparing for a high-stakes client meeting.

The Future of Enterprise AI Depends on Smarter RAG Solutions
Today’s enterprise leaders ask how to make AI meaningful, responsible, and scalable. One architectural approach stands out as organizations look beyond isolated proof-of-concepts and begin embedding AI into workflows: Retrieval-Augmented Generation (RAG).